EMR Jupyter Notebook: PySpark Imports Work in Shell, Not in Notebook- Issue is importing custom files
Issue: PySpark works in the first cells (likely SparkSession creation) but throws import errors when using my Python files in later cells.
Environment: AWS EMR ( Amazon EMR version emr-6.4.0 Installed applications JupyterEnterpriseGateway 2.1.0, JupyterHub 1.4.1, Spark 3.1.2)
Question: Why the import issue with custom files? Best practices for importing Python files in EMR notebooks?
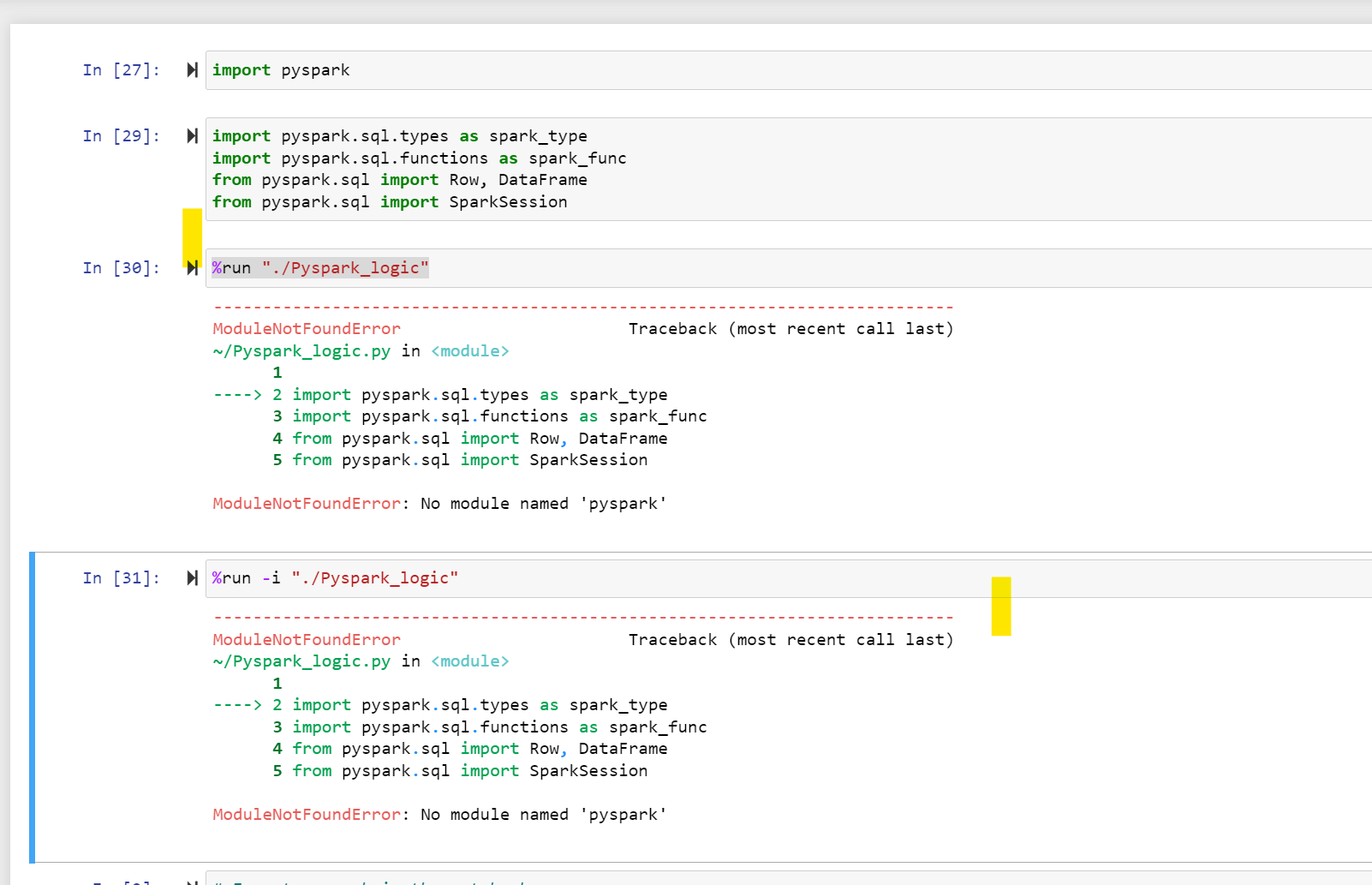
I tried all the possible ways of exporting like %run .. %run -i
- Mais recentes
- Mais votos
- Mais comentários
Hello Harish, The observation that you have experienced is an expected behavior. I have tried the below and one hack that you can do is
#!/usr/bin/python
import sys
import os
sys.path.append('/usr/lib/spark/python/lib/pyspark.zip')
sys.path.append('/usr/lib/spark/python/lib/py4j-src.zip')
os.environ['SPARK_HOME'] = '/usr/lib/spark'
import pyspark.sql.types as spark_type
import pyspark.sql.functions as spark_func
from pyspark.sql import Row
from pyspark.sql import SparkSession
My tests:
- in EMR master node, created script
test.py
[hadoop@ip-172-31-41-141 ~]$ cat test.py
#!/usr/bin/python
import sys
import os
sys.path.append('/usr/lib/spark/python/lib/pyspark.zip')
sys.path.append('/usr/lib/spark/python/lib/py4j-src.zip')
os.environ['SPARK_HOME'] = '/usr/lib/spark'
import pyspark.sql.types as spark_type
import pyspark.sql.functions as spark_func
from pyspark.sql import Row
from pyspark.sql import SparkSession
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master('yarn') \
.appName('pythonSpark') \
.enableHiveSupport() \
.getOrCreate()
data = [("Java", "20000"), ("Python", "100000"), ("Scala", "3000")]
df = spark.createDataFrame(data)
df.show()
- From notebook

- From YARN RM UI

The reason is the notebook is run on JupyterEnterpriseGateway (JEG) and EMR cluster is accessed via livy.
In many cases %run is being used to execute a different notebook see here instead of directly calling the python file.
But, generally with EMR its recommend to use %execute_notebook to execute ipynb files
Conteúdo relevante
 AWS OFICIALAtualizada há 2 anos
AWS OFICIALAtualizada há 2 anos- AWS OFICIALAtualizada há um ano
- AWS OFICIALAtualizada há um ano
- AWS OFICIALAtualizada há um ano